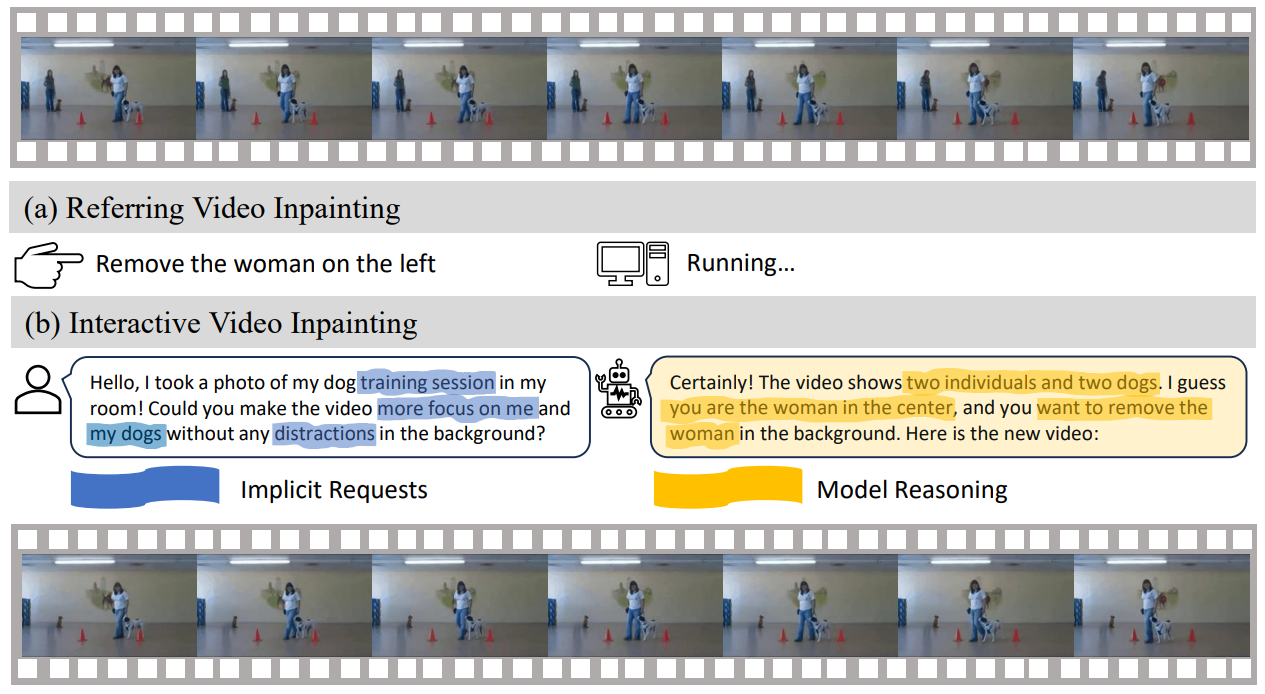
In the field of video inpainting, traditional methods rely on pre-computed binary masks to identify areas for restoration. The mask labeling process can be time-consuming and labor-intensive, particularly in applications like object removal. This paper introduces a pioneering language-driven video inpainting task that leverages natural language instructions. Our proposed language-driven video inpainting task uniquely utilizes natural language, including chatstyle conversations, to guide the inpainting process. To support this innovative approach, we develop the Remove Objects from Videos by Instructions (ROVI) dataset, comprising 5,650 videos and 9,091 inpainting results, specifically tailored to facilitate training and evaluation in this new paradigm. We present a novel diffusion-based language-driven video inpainting framework, representing the first end-to-end baseline for this task. This framework is distinguished by its integration with Multimodal Large Language Models, which enables it to comprehend and effectively process complex language-based inpainting requests. Our comprehensive evaluation, encompassing both quantitative metrics and qualitative analysis, demonstrates the robustness and versatility of our dataset and the efficacy of our proposed model in handling a wide range of inpainting scenarios driven by natural language instructions.
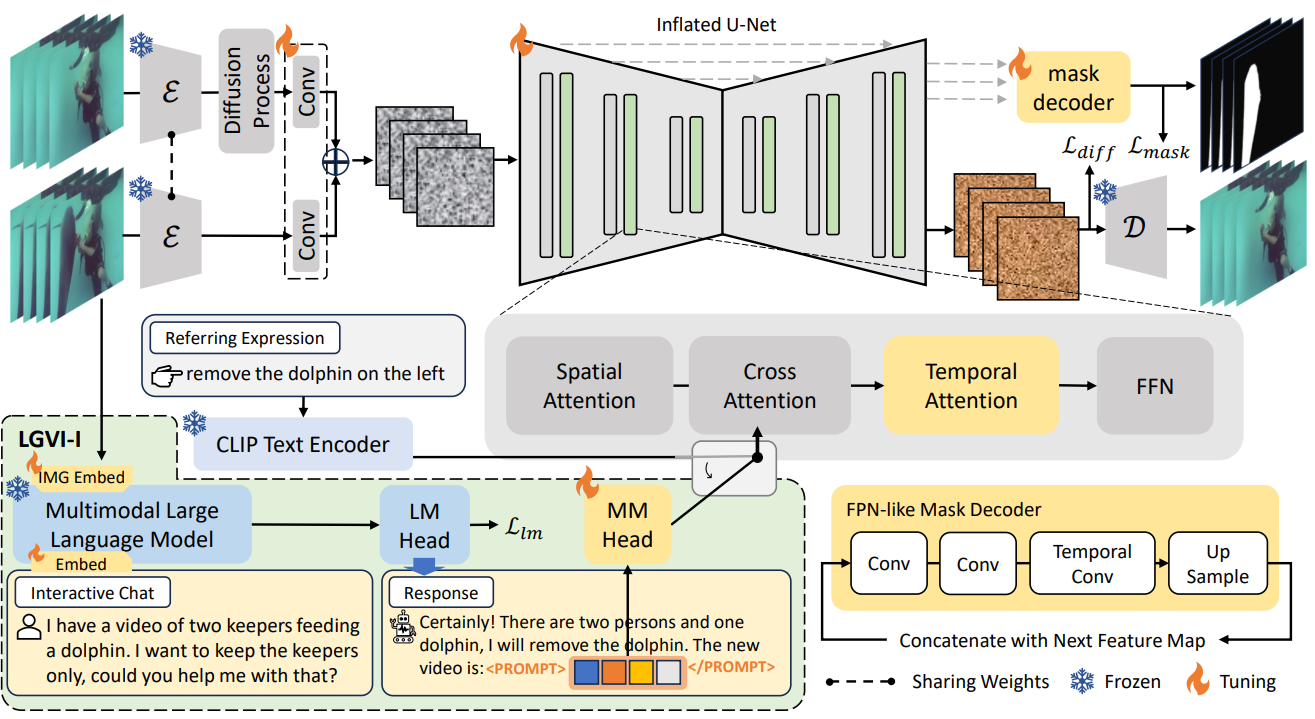
The proposed LGVI and LGVI-I framework. We inflate the U-Net with a temporal dimension to allow video input. To ensure temporal consistency in the generated videos, we introduce a temporal attention module between cross-attention and FFN layers. Additionally, we propose a mask decoder module for explicit guidance in inpainting tasks. We augment LGVI with MLLM joint training for interactive video inpainting, resulting in LGVI-I as the baseline. The output of MLLM includes a set of prompt tokens, which is fed into the cross attention of the U-Net.
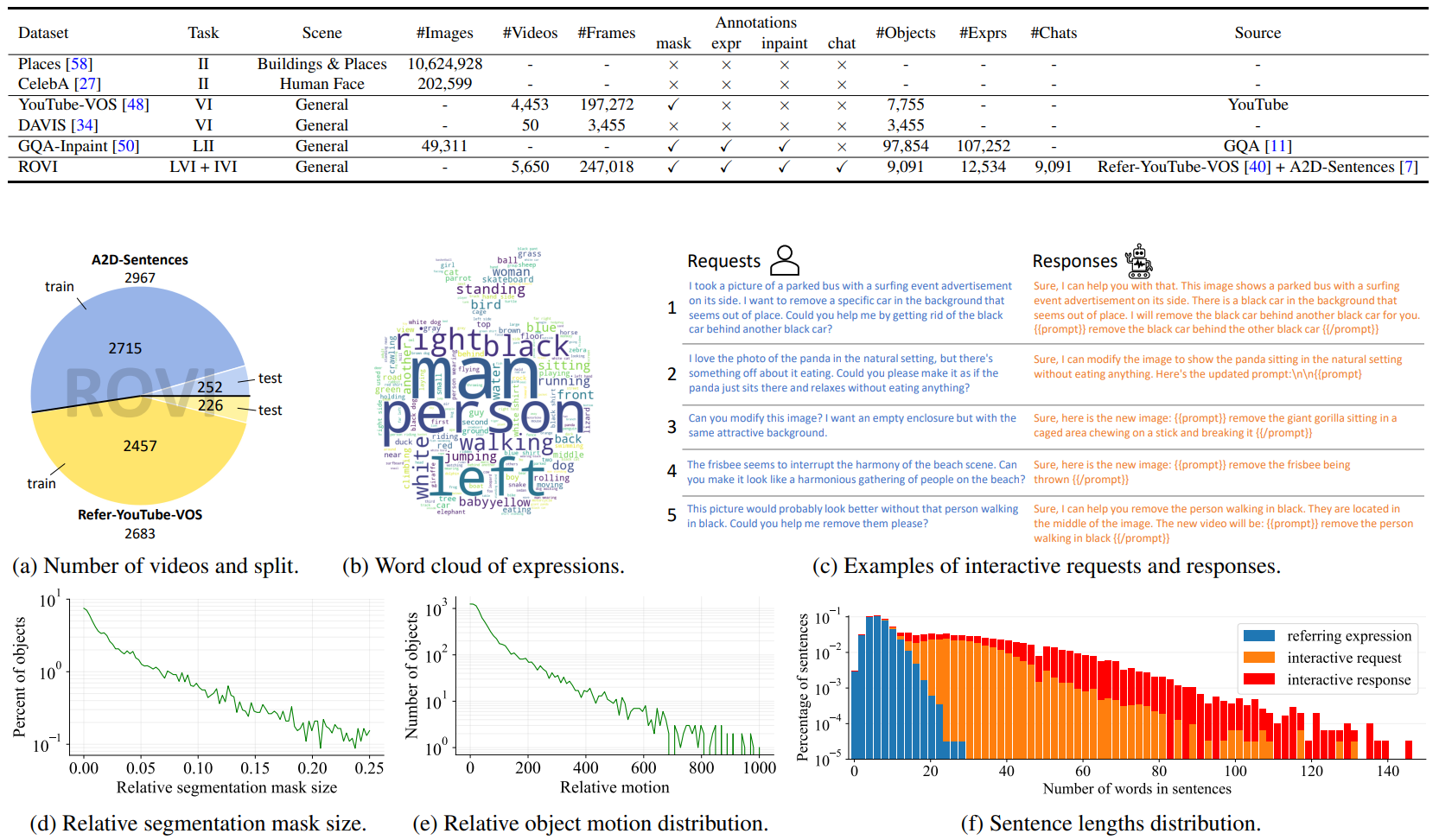
The statistics of the proposed ROVI dataset. Our ROVI dataset is the first for language guided video inpainting (LVI) and interactive video inpainting (IVI) tasks.
@article{Wu2023LGVI,
title={Towards Language-Driven Video Inpainting via Multimodal Large Language Models},
author={Jianzong Wu and Xiangtai Li and Chenyang Si and Shangchen Zhou and Jingkang Yang and Jiangning Zhang and Lining Li and Kai Chen and Yunhai Tong and Ziwei Liu and Chen Change Loy},
journal={arXiv pre-print},
year={2023},
}}